提升云端数据分析力微软Azure更新3大资料服务
微软
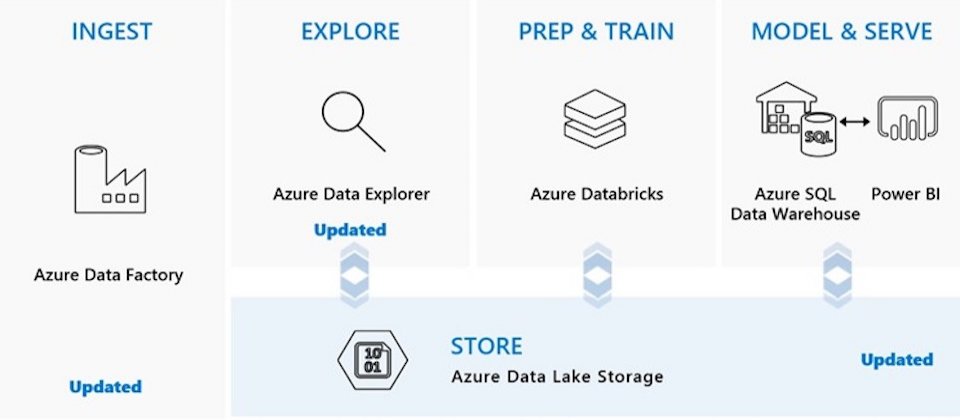
微软云端平台Azure最近宣布针对3项资料服务的更新,包含推出正式版的资料湖储存服务Data Lake Storage Gen2和资料完全託管服务Data Explorer,此外,还推出预览版的混合资料整合服务Data Factory,期望提供用户性价比高又安全的云端资料分析服务。
资料湖储存服务Data Lake Storage Gen2适用于巨量资料分析,结合了Azure非结构化储存服务Blob Storage的可扩展性、安全模型和丰富的功能于一身,再加上为分析所设计的高效能的档案系统,还能与Hadoop分散式档案系统相容,让用户选择云端资料湖服务时,不需要在成本和效能中取捨。
.png)
图片来源:微软
微软指出,自家资料湖储存服务其中一项主要目标,即是要与Apache生态系统相容,为了做到这点,微软开发Azure Blob档案系统驱动程式,该驱动程式正式成为Apache Hadoop和Spark的一部分,并且附于许多 Hadoop的商业版本中。
为了进一步提升Data Lake Storage Gen2的分析效能,微软用阶层式命名空间,收集档案集合并整理成阶层式目录和巢状子目录,此种命名空间对巨量资量分析架构相当重要,由于Hive或是Spark等工具经常将输出写入暂时位置,并在作业结束时重新命名该位置,若没有阶层式命名空间,重新命名所花费的时间通常会比分析流程本身更长,因此,阶层式命名空间因为需要较少的运算执行,能够加速job执行并减低成本。
而Data Explorer是一个快速且具有高扩展性的完全託管资料分析服务,能够针对大量的串流数据进行即时分析,在不需要修改资料结构的情况下,一秒内能够查询10亿笔记录,此外,该服务能与微软云端其他服务相连,像是Data Lake Storage、SQL Data Warehouse、Power BI。为了提升速度和简化操作,Data Explorer由两个分别的服务组成:Engine服务和资料管理服务,这两项服务都在Azure中,以运算节点的丛集形式部署。
.png)
图片来源:微软
资料管理服务负责消化多种不同型态的原始资料,并且管理资料清理、执行失败和backpressure等任务,还能透过自动索引和压缩机制快速处理资料。而Engine服务则是负责处理输入的原始资料和用户的查询,透过自动扩展(Auto Scaling)和资料分割(data sharding)来达到高效能的目标。
最后,微软这次的更新还推出混合资料整合服务Data Factory预览版,Data Factory服务是用来将资料移动和转换工作自动化的服务,内建超过80个与结构化、半结构化和非结构化资料源的连接器。除此之外,该服务还提供资料工作流程可视化工具Mapping Data Flow,提供用户在设计、建置和管理资料转换的过程有可视化的体验,不需要学习Spark或是对分散式基础架构有深入的了解。
.png)
图片来源:微软
免责声明:本文由用户上传,如有侵权请联系删除!
猜你喜欢
- 吃凤梨上火还是降火(cf雷神好还是黑龙好)
- 售楼小姐挣钱吗(真赚钱售楼小姐的一个月工资多少)
- 机动战士高达OOV(审判者纳德雷高达)
- 儿子结婚邀请函简短大气(儿子结婚邀请函简介介绍)
- 小鱼儿与花无缺林志颖版本(小鱼儿与花无缺林志颖版的现在怎么看不了了)
- msduo记忆棒(MSD记忆棒是什么东西啊)
- 巴西最重要的矿产资源(巴西最大的铁矿山是.","titletext":"巴西最大的铁矿山是.)
- 药水哥的直播在哪里看(药水哥在哪直播简介介绍)
- 我想要军装下的绕指柔得全部番外可不可以给我一份呢(我邮箱xinya12@sina.com)
- 爸爸见义勇为的作文(结尾处感想100字怎么写)
- 战鼓电影结局是什么(战鼓这部影片讲的是什么)
- start(king fx和shinee一起来的是哪期)
最新文章
- 个性标签写什么好8个字(个性标签8个字简介介绍)
- 贴吧和i吧有什么区别(贴吧和i吧有什么区别)
- 东北话得细小是什么意思(东北话小得得是啥意思)
- 太姥山旅游最新攻略一日游(太姥山旅游线路)
- 12月有什么好电影上映(12月上映好看的电影)
- 妒海主题曲百度云(泰剧妒海的主题曲和片尾mp3格式的谁有谢谢)
- 元奎在好莱坞拍过多少电影(指导过多少电影 都叫什么)
- 怎么关闭wps删除提示(wps屏幕提醒怎么关闭简介介绍)
- 4399弹弹堂vip折扣券(4399弹弹堂怎么刷点券啊)
- 企业天猫入驻条件及费用(天猫入驻条件及费用简介介绍)
- 尹相杰母亲是马玉涛吗(尹相杰母亲是马玉涛吗)
- 冬至应该吃什么食物(冬至应该吃什么食物)
- nokia6600复刻版本(NOKIA6630~~~)
- 新年快乐日语怎么说(新年快乐日语怎么说)
- 工作交接清单怎样写,格式是怎样的(工作交接清单怎样写格式是怎样的简介介绍)
- 为什么我的梦幻诛仙人物快捷键用不出来(求高手解答 我换了很多台机子了)
- 三星note3开不了机(三星note1手机为什么开不了机)
- 迅雷种子怎么提取(前缀是什么)
- poison(ivy 什么意思)
- 魔法卡片掉卡规则(魔法卡片中怎么没有变闪卡的卡友)
- 眼部结构简图(眼部结构简介介绍)
- 武汉外高国际部学费(武汉外高出国)
- 湖南台为什么叫马桶(湖南台为什么叫芒果台)
- 公元前10000年是什么年(公元前10000年)